Docker and Kubernetes platforms are a hot topic, yet there still seems to be some confusion about how they relate to one another. Do you need Docker if you have Kubernetes? We can clearly spell it out for you—it all comes down to the level of complexity you are dealing with.
Vanilla Docker vs Kubernetes Orchestrated Docker Containers
Before we answer the central question, it may be helpful to cover a bit of the basics and some industry history to understand how each technology relates.
Let’s start with vanilla Docker. For us, that means the deployment of containers without a centralized orchestration engine. Docker containers are deployed manually with a “docker run” command or with a tool like Ansible, Chef, docker-compose or any other non-cloud-native configuration management software. All these tools provide support for container creation, configuration, and lifecycle management.
But should you maintain your own fleet of servers for hundreds of containers using Ansible playbooks, Chef recipes, or docker-compose manifests? In short – you don’t want to. Maintaining these static configuration management playbooks and manifests (or worse, custom Python/Ruby/Shell scripts) is troublesome, error-prone, and a waste of valuable and limited engineering team resources. This is where automation, in the form of Kubernetes, comes in.
To better understand the importance and context of the orchestration layer, recall what led to the creation of container technology, and why the developer community embraced Docker so enthusiastically.
Virtualization: From one server per app to multi-tenancy
Between 1995-2001, running any web server—whether Apache for PHP or Tomcat for Java or any other business software for that matter—required a fully dedicated hardware server. There was no way to share server resources for different applications. Between 2001-2010, virtualization technologies such as Xen, VMware ESXi, and KVM became popular allowing server administrators to share workloads of different operating systems on the same hardware servers, yet stay fully isolated. This ability set the stage for private and public clouds like AWS, Rackspace, Azure, Google Cloud, etc. The cloud-enabled companies to easily and safely share computing capacity while ensuring complete separation in multi-tenant public clouds that reside on the same hardware—a revolution!
Containers, the new VMs
Around 2006, support for containers in the Linux Kernel was introduced and expanded over the years. While sharing the same host kernel, containers require less overhead and are much more lightweight than VMs. By isolating processes and underlying filesystems, they eliminate dependency hell and allow for portability—yet another IT revolution. Though not yet widely adopted, usage is rapidly increasing. Most enterprises run at least some workloads in containers, even if not yet in production. One of the common use cases are CI/CD systems and their “builders”/ “slave nodes”. For example, TeamCity or Jenkins worker nodes that run software builds and unit tests, can be created and destroyed on demand within seconds after new code was pushed to a repository. They will share the same hardware, allowing for effective utilization of compute resources and helping to avoid costly overprovision for peak times when all developers run their builds in the afternoon. The “builders/slaves” containers will spawn on demand and run all needed builds, sharing the same pool of physical or virtual machines, but running in parallel, greatly shortening the waiting time for all builds and tests to complete. It minimizes wasted developers time, especially when their CI/CD pipelines are parallelized to take advantage of the lightweight container builders that are quick to spawn by the hundreds and as easy to terminate when all tasks have completed.
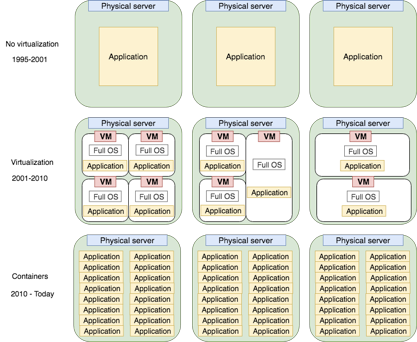
As companies containerize their applications, they quickly realize that managing them without automation is time-consuming and inefficient, and surely not scalable. Just as VMs need some kind of “control plane” like VMware VSphere or OpenStack (which help to manage all aspects of virtual machines, like snapshotting, recovery, access control, migration between physical hosts), containers require an orchestration tool if they are to scale. This is where container orchestrators come in. Without a feature-rich and easy to use control plane, it is practically impossible to maintain a large fleet of deployed containers. Using orchestrator like Kubernetes will enable the following benefits:
- constant health check of applications running in containers
- automatic recovery in case of failures
- autoscaling the number of containers based on custom application metrics like latency or CPU load
- constant monitoring and workload rebalancing across multiple hosts
- centralized logging and metrics aggregation
- requests load balancing across the containers
- smart routing with rack and zone awareness
- and much more.
Container Orchestration and the Rise of Kubernetes
To run containers at scale, you’ll need an orchestrator. Without it, quickly reacting to failures, automatically scaling up and down, and running replicas to use available cloud resources and avoid costly over-provisioning often overwhelmed operation teams. Container orchestrators automate everything from scheduling, scaling, health monitoring and restarting (self-healing) containers. Some orchestrators like Kubernetes also add desired state management as an additional benefit. Without an orchestrator, it will be nearly impossible to manage a large number of containers across a large set of physical or virtual machines.
Kubernetes, Docker Swarm, Hashicorp Nomad, Mesos, as well as a few other container orchestrators looked to solve those issues. Their main goal: provide resiliency, high availability, self-healing, and autoscaling of containerized workloads. Developed by Google, Red Hat, among other well-known contributors, and adopted by all major cloud providers, Kubernetes became the de facto container orchestrator in 2017. Through combined efforts, the open source community created a feature-rich yet complex container orchestrator framework. That complexity was outlined by Google’s Kelsey Hightower in a 14-point tutorial, “Kubernetes the hard way”. Organizations often underestimate the time, resources, and in-house expertise required.
Docker and Kubernetes are only a part of the puzzle
We know now that deploying Docker at scale requires Kubernetes. But what’s with all these container management platforms that keep popping up? Well, Docker and Kubernetes are only part of the puzzle. You’ll need logging, monitoring, security, governance, integration with RBAC, etc. Additionally, you’ll need to keep up with Kubernetes’ quarterly updates. In short, it requires a lot of internal expertise and resources to manage reliable, secure clusters across your enterprise. Numerous companies have tried to go the build-it-yourself route, failed, and came to the realization that they needed a platform. Let’s look at their value add.
Enterprise container management platforms simplify adoption and management by automating cluster configuration and management. They ensure all clusters deployed have everything they need to run in production without the need for additional configuration. Whether pre-configured memory and CPU usage dashboards, logging and monitoring or role-based access control, an enterprise platform must check multiple marks to be considered truly production ready. Learn what the key considerations are when selecting a production-ready Kubernetes platform.
What’s the Kublr approach?
Our goal at Kublr is to provide the most comprehensive container management platform while keeping the open source promise of flexibility, openness, and modularity. Kublr provides IT with a user-friendly platform to deploy, run, and manage stable production grade Kubernetes clusters on their own infrastructure whether in the cloud, on-premise or hybrid environments.
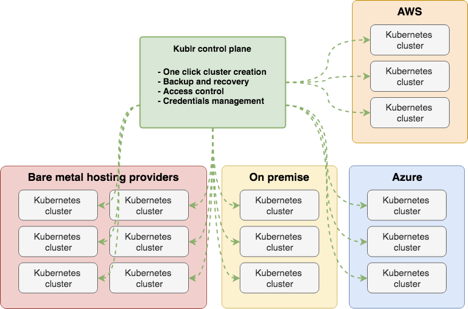
While pre-configured for the most common use cases of large enterprises, Kublr also allows for cluster customization for more advanced use cases. IT can easily deploy multiple enterprise-grade Kubernetes clusters with centralized logging and monitoring, role-based access control on a multi-cluster level, and single sign-on for all services. It can be self-hosted on your servers, even in completely isolated on-premise environments for highly sensitive data.
Managing unlimited numbers of clusters, Kublr frees Ops and DevOps teams up to focus on their competitive edge instead of maintaining and troubleshooting individual Kubernetes components which eats up hours when done without a production ready enterprise container platform.
So it’s not a question of Docker vs Kubernetes—or enterprise container platform for that matter. Instead, these technologies can be seen as an inverted pyramid with each layer providing additional abstraction and enterprise features. Unless you are a Google, Netflix or Amazon, you will likely opt for an enterprise container platform. Vanilla Kubernetes is just too complex and time-consuming to configure and maintain. Plus, the needed level of Kubernetes expertise is still rare and expensive. We recommend spending those resources on developing new features that will delight your customer base. If you’d like to see our Kublr in action our team can walk you through a demo of all features. Just shoot us an email!