
News of the latest Apache Spark release and its native Kubernetes support excited the whole open source community. Thanks to the new software, there is now first-class support for data processing, data analytics, and machine learning workloads in Kubernetes. Suddenly, Kubernetes is much more accessible to data scientists, enterprise companies, and even startups trying to make sense of data.
This post offers background about data science (and big data), and an introduction to Spark and its architecture, shedding some light over why there is so much excitement. Even if you don’t have a Kubernetes cluster, or would like to have one but don’t know how, there’s a quick and easy solution. Kublr can help you deploy a fully functional cluster in mere minutes. In our follow-up post, we’ll walk you through how to run Spark 2.3 in Kubernetes using Kublr.
Background
Big data, predictive analytics, and other methods are more popular than ever due in part to cheap and ubiquitous connected sensors in mobile devices, software logs, cameras, microphones, RFID readers, and wireless sensor networks. IDC has predicted that there will be 163 zettabytes of data by 2025. Such a huge amount of data is a challenge, often requiring “massively parallel software running on tens, hundreds, or even thousands of servers.” Only the largest organizations have those resources.
In 2004, Google published a paper on a process called MapReduce. This framework generates data sets with a parallel, distributed algorithm on a cluster. With MapReduce, queries are split and distributed across parallel nodes (the Map step), with the results then gathered and delivered (the Reduce step). The success of MapReduce quickly led to imitators like Hadoop, an Apache open-source project. The core of Apache Hadoop combines the Hadoop File System (HDFS) and a MapReduce programming model. Hadoop splits files into large blocks and distributes them across nodes in a cluster. The packaged code is then transferred into nodes to process the data in parallel.
The power of this tool is self-limiting, however. It reads inputs and stores the reduction results, restricting processing to the latency of the storage platform hosting its data. To overcome this limitation, in 2009, the AMPLab at University of California, Berkeley, developed Spark. Spark is a general-purpose, in-memory, data processing engine based on the resilient distributed dataset (RDD), a read-only multiset of data points distributed over a cluster of machines. The Berkeley team claims in its paper that Spark can process data up to 100 times faster than Hadoop and 10 times faster if processing disk-based data in a way similar to MapReduce. Though not entirely a fair comparison, it still impresses developers, and its architecture is worth discussing.
Architecture
Much like MapReduce, Spark distributes data across a cluster and process that data in parallel. Spark consists of the following components:
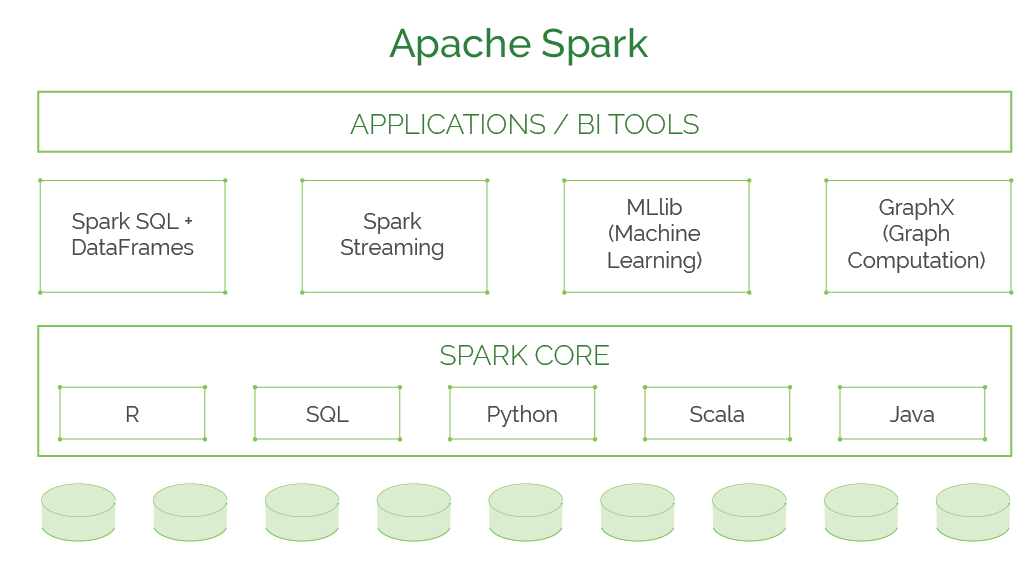
- Spark Core: The foundation of Spark, Spark Core provides distributed task dispatching, scheduling, and basic I/O exposed through an application programming interface centered on the RDD abstraction. This interface mirrors a functional/higher-order model of programming: a “driver” program invokes parallel operations such as map, filter, or reduce on an RDD by passing a function to Spark, which then schedules the function in parallel on the cluster.
- Spark Streaming: This feature analyzes real-time streaming data by ingesting information in mini-batches and performing RDD transformations. Doing so enables the same set of application code written for batch analytics to be used in streaming analytics, making it easy to implement lambda architecture.
- Spark Machine Learning Library (MLlib): A library of prebuilt analytics algorithms that can run in parallel. Many common machine learning and statistical algorithms have been implemented, including summary statistics, correlations, stratified sampling, hypothesis testing, random data generation, classification and regression, collaborative filtering techniques, cluster analysis methods, dimensionality reduction techniques, feature extraction, and optimization algorithms.
- Spark SQL: Spark SQL is a component on top of Spark Core that introduces a data abstraction with support for structured and semi-structured data called DataFrames. Spark SQL provides a domain-specific language (DSL) to manipulate DataFrames in Scala, Java, or Python. It also provides SQL language support with command-line interfaces and ODBC/JDBC server. In Spark 1.6, a new interface called DataSet was added to provide the benefits of RDDs (strong typing, ability to use powerful lambda functions) with the benefits of Spark SQLʼs optimized execution engine.
- GraphX: A graph analysis engine and analytics algorithms running on Spark. Because it is based on immutable RDDs, the graphs are immutable too, making GraphX unsuitable for graphs that need to be updated. GraphX provides two separate APIs for implementation of massively parallel algorithms (such as PageRank): a Pregel abstraction, and a more general MapReduce- style API.
Apache Spark requires a cluster manager and a distributed storage system to operate. For distributed storage, Spark can handle Hadoop Distributed File System (HDFS), MapR File System, Apache Cassandra, OpenStack Swift, and Amazon S3. For cluster management, Spark supports standalone (which is the native Spark cluster), Hadoop YARN, or Apache Mesos.
Traditionally, data processing workloads have been run in dedicated setups like the YARN/Hadoop stack. However, unifying the control plane for all workloads on Kubernetes simplifies cluster management and improves resource utilization.
Spark 2.3. What’s New?
Those changes have arrived with Spark 2.3. Now, users can run Spark workloads in an existing Kubernetes 1.7+ cluster and take advantage of Apache Sparkʼs ability to manage distributed data processing tasks at the same time. Apache Spark workloads can make direct use of Kubernetes clusters for multi-tenancy and sharing through Namespaces namespaces and Quotas. They can also handle administrative features such as Pluggable Authorization and Logging. Critically, the upgrade doesn’t require any changes or new installations on your Kubernetes cluster. All a user needs to do is create a container image and set up the right RBAC roles for the Spark Application, and everything is in place.
A native Spark Application in Kubernetes acts as a custom controller, which creates Kubernetes resources in response to requests made by the Spark scheduler. In contrast to deploying Apache Spark in Standalone Mode in Kubernetes, the native approach offers granular management of Spark Applications, improved elasticity, and seamless integration with logging and monitoring solutions.
Here’s how it works (as shown in the picture below):
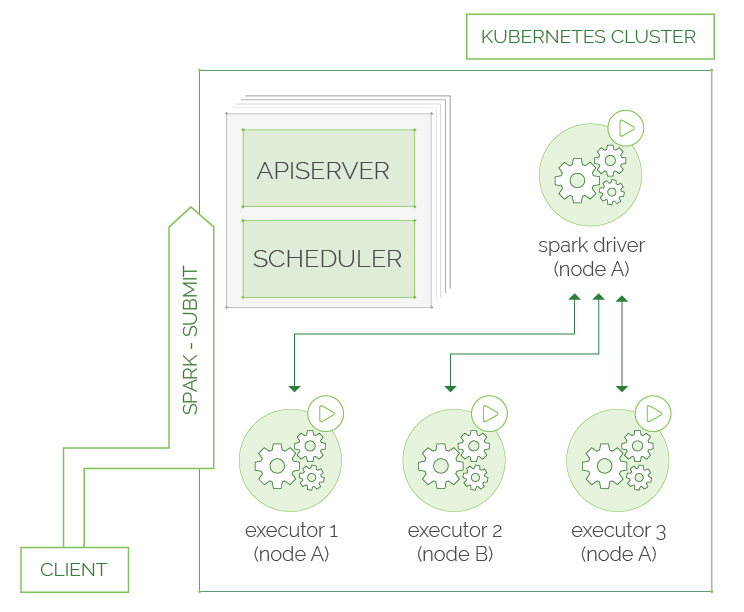
- In Spark, spark-submit can be directly used to submit a Spark application to a Kubernetes cluster.
- After submitting, Spark creates a Spark driver running within a Kubernetes pod.
- The driver creates executors, which are also running within Kubernetes pods, connects to them, and executes application code.
- When the application finishes, the executor pods terminate and are cleaned up, but the driver pod persists, logs, and remains in “completed” state in the Kubernetes API until collected or manually cleaned up.
Kubernetes requires users to supply images that can be deployed into containers within pods. The images are built to be run in a container runtime environment that Kubernetes supports. Spark ships a script (bin/docker-image-tool.sh ) to build a Docker image and publish it in the Kubernetes backend.
But, it is not only that. Apache Spark 2.3 also has the following changes:
- ML Prediction now works with Structured Streaming. It includes a new Spark History Server (SHS) backend.
- It has an experimental API for plugging in new data sources in Spark.
- A new execution engine can execute streaming queries with sub-millisecond, end-to-end latency.
You can read the official release notes here.
Native integration with Kubernetes enables Spark to leverage Kubernetes strengths in scheduling clusters, cluster auto-scaling (adding more nodes to a cluster when needed), and pod clean up across on-premise and cloud environments. Want to get your hands dirty? Here is a hands-on tutorial that walks you through running Spark with Jypiter Notebook on Kubernetes.