
If your organization leverages technology as a differentiator, a DevOps approach to application and service delivery is inevitable. The benefits are just too great. Whether it is the ability to innovate, decrease time to market, or improve code quality and employee satisfaction, if your competitors adopt it, so must you. But what does it take to transition to a DevOps-enterprise?
In part one of this article, we discussed how DevOps relates to digital transformation. We explored what IT looked like prior to DevOps, what DevOps is, and how it came to be.
In this article, we’ll dive a little deeper and outline what it takes to implement a DevOps approach, including automated tests for continuous feedback, ideal team structures and architectures, integrating security, as well as automated platforms and telemetry.
The Six Essential Building Blocks of DevOps
DevOps is not simply a technology stack. It’s an approach that combines cultural philosophies, organizational change, and the implementation of new tools and practices.
This sounds like a mammoth undertaking, but let’s break it down into six understandable building blocks.
1. Small Teams, Full Ownership
Traditionally, code development involved numerous tightly coupled teams that depended on each other to complete their work. Wait time was a huge issue as people became inevitable bottlenecks.
DevOps team structures, on the other hand, encourage generalists who handle smaller functionalities and own the entire process from Dev to Ops. That’s because over-specialization leads to silos with multiple handoffs and queues, which leads to prolonged lead times. That doesn’t mean highly specialized engineers are obsolete. On the contrary, technology is getting increasingly specialized and we do need expertise more than ever. However, you don’t want engineers who can only contribute in one area. That means, the organization must encourage professional learning and growth so their staff can become rounded experts.
2. Automated Tests for Continuous Feedback
In IT, poor outcomes are generally due to a lack of fast feedback. It wasn’t uncommon for developers working on waterfall projects, the methodology used prior to Agile, to develop code for a year before sending it to QA for testing. Seeing test results this late in the game means developers may have been working on faulty code all year long without knowing it. As you can imagine, finding the source of the error and fixing it a year later is no easy task.
Addressing this is at the core of DevOps. It aims at providing fast feedback loops whenever work is performed so developers can fix errors when and as they occur. This means developers must be able to perform tests themselves instead of depending on a separate team to do so. This can be achieved through automated tests that detect issues immediately, so they can be fixed before more work is done as well as prevent developers from repeating the same error again.
The bigger the system, the more changes are tested or pushed into production, the more difficult it is to identify where the problem comes from.
By identifying and fixing the problem immediately versus working around it and fixing it later, learning is improved. The more time lapses between work and feedback, the more likely critical information will be lost due to fading memories or changing circumstances.
But how soon after new code is introduced can tests uncover issues? Obviously, the sooner the better. A mature DevOps friendly QA process relies on tests on all levels — from unit testing built into the build process to manual QA tests run by a QA team (there are still some tests that will be manual).
Unit tests play a major role here. A unit is the smallest testable part of any software and thus the minimal viable code on which tests can be performed.
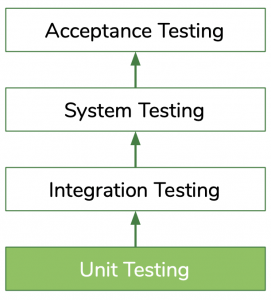
Experience has also shown that when developers share responsibility for quality, outcomes improve and learning accelerates. For that to happen, feedback must come in minutes, not months, however.
3. Loosely-Coupled Architectures
In tightly coupled architectures, small changes can lead to disastrous failures. System changes or updates demand close coordination with everyone else working on that system and could thus be affected. This leads to a complex change management process. But even then, once code is ready for production, new code from other groups has already been introduced. This means you are inevitably releasing your code into a system that differs from the one you tested it for. The bigger the system, the more changes are tested or pushed into production, the more difficult it is to identify where the problem comes from. Any change, no matter how small, represents a risk and managing that process is incredibly stressful.
A DevOps-oriented architecture enables small teams to implement, test, and deploy code safely and quickly, increasing productivity and outcome. This is enabled by service-oriented architectures (SOA) which are loosely coupled. Loosely coupled means that components (or services) are isolated within containers and thus not affected by changes around them — everything they need is in the container. Interacting strictly through application programming interfaces (APIs), they don’t share data structures or database schemata. The result: a bounded context with compartmentalized and well-defined interfaces that fosters flexibility and scalability, even in huge enterprises with thousands of developers all continuously deploying code into the same system.
4. Telemetry for Feedback on Apps in Production
When you have code in production, things will go wrong — there is no way around it. To fix it, you need to identify the source first, and to do that, you need data.
Back in the days, IT would reboot servers one-by-one, until the problem was fixed. While that sounds crazy, especially if you’re dealing with mission-critical apps, that was the fastest option to get the systems up and running again. Logging and monitoring tools weren’t as sophisticated, so IT didn’t have the necessary telemetry (i.e. data) that would quickly point them to the likely source. Rebooting was the fastest way to restore services, so that’s what they did.
Today, things have dramatically changed. New logging, monitoring, and alerting tools help IT understand contributing factors and detect issues early on, ideally before customers are impacted. These tools continuously and automatically collect and send measurements and metrics to a monitoring tool. If a deviation occurs, the system alerts IT so they can look into it. With enough data points, IT can confirm when services are operating correctly and flag when a problem occurs so that corrective action can be taken immediately. Setting up these tools and visualizing telemetry through dashboards to the entire team is a key aspect of DevOps.
5. Continuous Organization-wide Learning
Although the goal is to catch issues before they are deployed, errors do slip through. That’s why developers must be able to self-diagnose problems, solve them, and share lessons learned throughout the organization. For the latter to happen, you’ll need to develop a system of learning where mistakes and preventive actions are captured and made accessible across the IT department with the goal of becoming a resilient organization.
6. DevSecOps: Building Security into Your DevOps Approach
One critical aspect that was initially not taken into account when DevOps started out, is security. The DevSecOps trend is rectifying it by extending the DevOps approach and integrating security into developers and operations’ daily work.
The typical personnel ratio between development, operations, and infosec is about 100:10:1. You are probably wondering how on earth can one person possibly ensure that a system built by a hundred is secure. The answer is compliance checking after the fact. Once code is deemed ready to be deployed by dev and ops, infosec checks it. If an issue is identified — and they often are — work is sent back for rework. Clearly, the process of continuously sending work back and forth is inefficient, expensive, and creates tension between teams.
Solving this requires the same approach that DevOps introduced. DevOps ensures that operational requirements are built-in from day one. The same must now be done with security requirements — that’s the gist of DevSecOps. It extends DevOps to include security by automating and integrating it into development and operations through automated infosec tests that run along with all other automated ops tests. Additionally, infosec and developers collaborate early on to ensure security and compliance objectives are met from the get-go.
Getting Started with DevOps: Your Toolkit
To implement a successful DevOps approach, all the above-mentioned areas are key. While DevOps is all about small teams that work on small functionalities from start to finish, who are encouraged to learn from their mistakes and share them throughout the organization, none of it is possible without the appropriate DevOps toolkit. You’ll need to:
- Containerize your applications and start refactoring them so they are slowly broken down and decoupled from one another.
- Build a cloud native infrastructure platform on which your apps will run which allows for on-demand environment creation.
- Build a deployment pipeline with automated tests to validate code works as planned.
- Build centralized logging and monitoring tools within all platforms to gather accurate telemetry.
Hence, the first step is to make your legacy applications cloud native compatible. You’ll need to containerize them and start breaking them down. There is no need to rebuild them. Instead, you’ll start refactoring small and safe components first and, once you’re confident, you move to more critical pieces. The remaining can stay as is as you start (but containerized!). You can then iteratively refactor them in a prioritized way.
Which leads to the next step, building your enterprise platforms:
Centralized DevOps Platforms for Increased Dev Productivity
To enable DevOps team structures, a completely new set of centralized platforms and services are needed. Developers must be able to independently create production-like environments, run tests, and deploy code — all which should be (ideally) automated and available on-demand. No team should depend on QA or operations to proceed with their work. A key goal of DevOps is to eliminate human bottlenecks.
Developing and maintaining these platforms and tools is real product development and will require time and resources — especially if you do it right. But, as the annual State of DevOps reports prove time and time again, it’s well worth the effort.
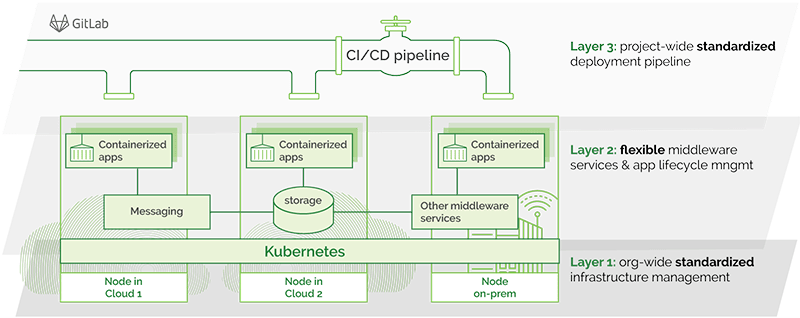
Kubernetes-Powered On-Demand Production-Like Environments
Traditionally, developers had to request staging or testing environments from the operations team — a request that would first land in a (long) queue. Waiting weeks, sometimes even months to get an environment was completely normal.
On-demand production-like environments eliminate that bottleneck. Through a UI, developers spin up environments as needed. These have been pre-configured by operations to mimic production parameters, enabling development and tests in production-like conditions. This is done via an infrastructure management platform that goes way beyond on-demand environment creation. While its main goal is to ensure reliable, secure application deployment, it should also have a self-service ability for developers. You want the same conditions in testing as in production, remember? Hence, the same toolkit should be used to create ALL environments.
If you talk to IT regularly, you’ve probably heard of Kubernetes. This is exactly where it fits in. Kubernetes is at the core of most cloud native architectures today. An open source project with incredible traction, Kubernetes runs across your entire infrastructure, managing the underlying resources and acting like some sort of datacenter operating system. (To learn more about it, please refer to our Kubernetes primer.)
IT can either build such a platform in-house (most don’t due to resource constraints and a lack of internal expertise — Kubernetes is still new to most) or select a vendor-supported platform. Kublr, for instance, is an enterprise-grade Kubernetes platform that doesn’t compromise Kubernetes’ inherent flexibility and openness. No matter which Kubernetes platform you choose, never sacrifice those key characteristics — they are what will enable you to pivot with market demands.
Building a Deployment Pipeline or Continuous Integration, Continuous Delivery (CI/CD)
In IT, multiple developers generally work on different parts of a system in parallel. Each developer works on their own “branch” which must eventually be integrated with the version control “master branch” where all changes from all developers are merged before pushing into production (see image below with different dev branches and the blue master branch). The longer developers work on their own branch without committing to the master, the more difficult it is to integrate their changes. That’s because the master is continuously changing as different developers are committing their code. Hence, the longer developers wait to commit their code, the more will the master have changed, and the more likely issues will occur. This is the pain point continuous integration (CI) addresses.

Different branches of the Kublr Docs page: Blue is the master branch and all others are individual development branches. Developers work on their own workstation and merge their changes multiple times a day or by the end of the day.
To mitigate these integration problems, CI focuses on two things:
- Increase integration frequency and decrease batch sizes(amount of code committed). While integration problems are inevitable — after all the master keeps evolving — continuously integrating code into the master, leads to early issue detection (assisted by unit tests with high code coverage). Early detection makes a huge difference, especially if you’re only debugging a few lines of code.
- An automated deployment pipeline that enables developers to run fast, automated tests that validate that their code works with all dependencies and is good to be committed to the master. Automated tests are at the core of CI, without them, there is no CI.
Continuous delivery, the CD part of CI/CD, extends the deployment pipeline with automated production acceptance tests that validate that the code is in a deployable state. If passed, the code is automatically pushed into production. The goal of CD is to empower developers to self-deploy code to production and get immediate feedback to quickly fix any potential issue without having to go through operations.
To increase the flow of work — a core goal of CI/CD (and DevOps in general) — deployment should be ideally done without any manual steps or handoffs.
Pulling It All Together
As we have seen, DevOps is about culture change: small groups working on small pieces from start to finish while focusing on global goals. DevOps tools are used to reinforce this culture and accelerate desired behavior. Clearly, a change in human behavior is required. For that to be successful, you’ll need full leadership buy-in and top to bottom reinforcement.
On the technology side, if you don’t have the in-house expertise or resources, you can take advantage of programs such as Kublr Accelerators where a team of experts will help you transition to the new stack and build the needed platforms. Whatever you do, ensure you build a modular, open architecture. Today’s open source, cloud native technologies provide a huge opportunity to build flexible systems that allow you to pivot with market demands. Don’t jeopardize that long-term opportunity only to gain a few months today.