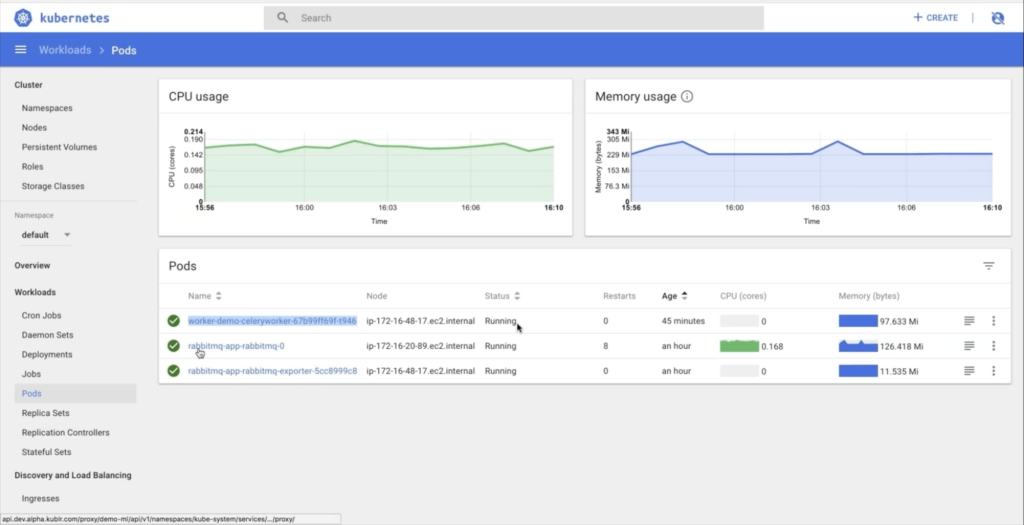
Enabling support for data processing, data analytics, and machine learning workloads in Kubernetes has been one of the goals of the open source community. During this meetup we’ll discuss the growing use of Kubernetes for data science and machine learning workloads. We’ll examine how new Kubernetes extensibility features such as custom resources and custom controllers are used for applications and frameworks integration. Apache Spark 2.3.’s native support is the latest indication of this growing trend. We’ll demo a few examples of data science workloads running on Kubernetes clusters setup by our Kublr platform.
Kubernetes, Data Science and Machine Learning
Enabling support for data processing, data analytics, and machine learning workloads in Kubernetes has been one of the goals of the open source community. During this meetup we’ll discuss the growing use of Kubernetes for…
More from the blog
DevOps Consulting
We help you navigate all the steps toward successful cloud-native transformation.