
Software is becoming a strategic competitive differentiator across industries — today’s race towards digital transformation is proof of it. Enterprises are investing (often millions of dollars) in technology to better serve their customer base. For business leaders, who play a key role in the decision-making and planning process, it’s indispensable to have a basic understanding of how business applications work. What are the organizational constraints and what opportunities do new technology developments bring?
In this article, we’ll provide a high-level overview of what a distributed system or application is. We’ll discuss characteristics, design goals and scaling techniques, as well as types of distributed systems. Finally, we will look into how cloud native technology is changing the status quo.
Leading up to the proliferation of distributed systems
Starting in the mid-1980s, two technology advancements made distributed systems feasible.
First, there was the development of powerful microprocessors, later made even more powerful through multicore central processing units (CPUs). This led to so-called parallelism where multiple processes run at the same time. A single core CPU, on the other hand, can only run one process at the time, although CPUs are able to switch between tasks so quickly that they appear to run processes simultaneously. As CPU capacity increased, determining the limit of a machine’s computational capacity, more powerful applications were developed.
The second key development was the invention of high-speed computer networks. Local-area networks (LAN) allowed thousands of physically close machines to be connected and communicate with each other. Wide-area networks (WAN) enabled hundreds of million of machines to communicate across the world. With literally no physical limit to computational capacity, enterprises were now able to create ‘super computers’.
Characteristics of a distributed system
A distributed system is a collection of autonomous computing elements that appear to its users as a single coherent system. Generally referred to as nodes, these components can be hardware devices (e.g. computer, mobile phone) or software processes. A good example is the Internet — the world’s largest distributed system. Composed of millions of machines, to you, it feels like a single system. You have no idea where the data is stored, how many servers are involved, or how the information gets to your browser. This concept is called abstraction and reappears over and over again in IT. In short, your browser abstracts away the complexity of the Internet. The same applies to applications like Gmail, Salesforce, or any enterprise application you may use. You literally interact with distributed applications every single day!
Nodes (machines or processes) are programmed to achieve a common goal. To collaborate, they need to exchange messages. Let’s say:
- Your browser sends a request to pull website information from a domain server (node A sends a request to node B);
- The domain server pulls the website info from its data store (node B processes the request),
- The domain server pushes the website code to your browser (node B sends a response to node A).
Clearly, communication is at the core of distributed systems; if it fails no collaboration is possible and your browser has nothing to display.
Middleware and APIs — the glue holding distributed systems together
Distributed systems often have a separate software layer placed on top of their respective operating system (OS) called middleware. It creates standards allowing applications that aren’t necessarily compatible to communicate. It also offers a variety of services to the applications such as security or masking of and recovery from failure.
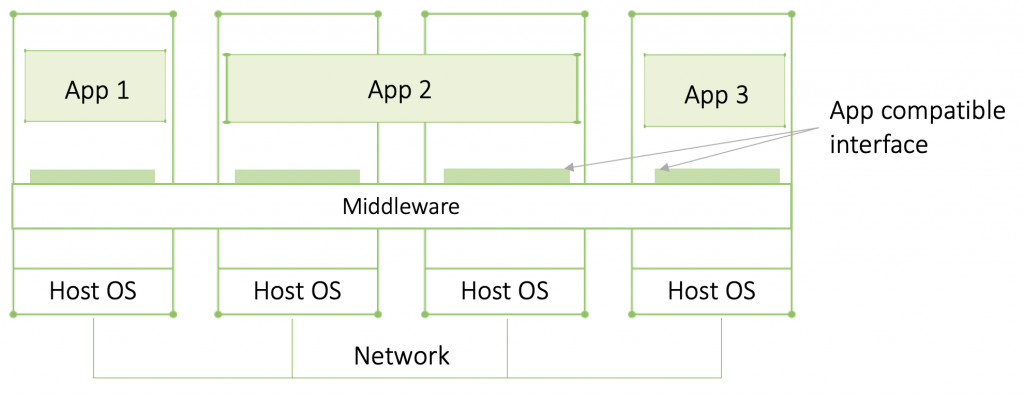
Today, we are hearing less about middleware and more about Application Programming Interfaces (APIs). APIs function as a gateway through which applications can communicate. It’s basically an application interface abstraction. For applications to communicate directly, they must have compatible interfaces which isn’t often the case. An API allows different applications to communicate through it. Hence, it abstracts away the implementation details and differences from the applications. Applications don’t need to know anything about other applications’ except for their API.
You may have heard about open APIs, there has been quite a bit of buzz around them, and with good reason. Some applications open up their APIs to the public so external developers can tap into their data. Google Maps and Yelp are a great example. Yelp taps into Google Maps’ API. You may have seen the little map next to the restaurant description. To get directions, you simply click on the map — how convenient! Open APIs have clearly made our lives a lot easier and, if you pay attention, you’ll see them at play everywhere.
While that doesn’t mean that middleware is facing extinction — it still has security, coordination, and management functions — APIs are largely substituting the communication aspect of it.
Design Goal
Distributed system have four main goals:
Resource sharing — Whether storage facilities, data files, services, or networks, you may want to share these resources among applications. Why? It’s simple economics. It’s clearly cheaper to have one high-end reliable storage facility shared among multiple applications than buying and maintaining storage for each separately.
Abstraction — to hide the fact that processes and resources are distributed across multiple computers, possibly even geographically dispersed. In other words, as just discussed above, processes and resources are abstracted from the user.
Openness — An open distributed system is essentially a system built by components that can be easily used by, or integrated into other systems. Adhering to standardized interface rules, any arbitrary process (e.g. from a different manufacturer) with that interface can talk to a process with the same interface. Interface specifications should be complete (everything needed for an implementation is specified) and neutral (does not prescribe what an implementation should look like).
Completeness and neutrality are key for interoperability and portability. Interoperability means that two implementations from different manufacturers can work together. Portability characterizes the extent to which an app developed for system A will work on system B without modification.
Additionally, distributed systems should be extensible, allowing teams to easily add new or replace existing components without affecting those components staying in place. Flexibility is achieved by organizing a collection of relatively small and easily replaceable or adaptable components.
Scalability — is needed when there is a spike of users that needs more resources. A good example is the increase in viewership Netflix experiences every Friday evening. Scaling out means dynamically adding more resources (e.g. increase network capacity allowing for more video streaming) and scaling back once consumption has normalized.
Scaling Applications
Let’s have a closer look at scalability. Systems can scale up or out. To scale a system up, you can increase memory, upgrade CPUs, or replace network modules — the amount of machines remains the same. Scaling out, on the other hand, means extending the distributed system by adding more machines. Scaling up, however, is commonly used to refer to scaling out. So if IT is talking about scaling applications up, they are likely referring to scaling out (the cloud has made that really easy).
Scaling out is particularly important for applications that experience sudden spikes, requiring a lot more resources but for a limited time only, like in our Netflix example. Data analytics tools, for instance, may suddenly require more compute capacity when real-time data generation spikes or when algorithms are run. Building applications with the full resource capacity needed during these spikes is expensive — especially if those spikes happen rarely. Scalability allows applications to dynamically add resources during a spike (scale out) and then return them to the resource pool once they aren’t needed anymore (scale in). This enables other applications to use them when they need more resources, significantly increasing efficiencies and reducing costs.
Scalability brings some challenges, however. Here are three techniques to address them:
Hiding communication latencies — when scaling applications out to geographically dispersed machines (e.g. using the cloud), delays in response to a remote-service request are inevitable. Networks are inherently unreliable leading to latencies that must be hidden from the user. This is where asynchronous communication can help.
Traditionally application communication was synchronous. Just like a phone line, synchronous communication is only possible while two processes are connected (two people speaking on phone). As soon as the connection drops, the message exchange stops. While connected, no further exchanges can happen (if someone else tries to call, it’ll be engaged). Delays in replies (latencies) means that processes remain connected waiting for the reply to arrive, unable to accept new messages, slowing the entire system down.
Asynchronous communication, on the other hand, is more like email. Process A sends a message into the network and doesn’t care if B is online or not. The message will be delivered to process B’s ‘inbox’ and processed when B is ready. Process A, meanwhile, can continue its work and will be notified once a response from B arrives.
Partitioning and distribution — is generally used for large databases. By separating data into logical groups, each placed on a different machine, processes working on that dataset know where to access it. Amazon’s global employee database, for instance, which is presumably huge, may be partitioned by last name. When a search query for ‘John Smith’ is executed, the program doesn’t have to scan all servers containing employee data. Instead, it will go directly to the server hosting data on employees whose last name starts with ‘s’, significantly increasing data access speed. This, by the way, is exactly how the Internet Domain Name System (DNS) is built. As you can imagine, it would be impossible to scan the entire internet each time you’re looking for a website. Instead, URLs indicate the path leading to the data.
Replication — components are replicated across the distributed system to increase availability. For example, Wikipedia’s database is replicated throughout the world so users, no matter where they are, have quick access. In geographically widely dispersed systems, having a copy nearby can hide much of the communication latency. Replicas also help balance the load between components, increasing performance. Think Google Maps. During rush hour, there is a huge spike of traffic data that needs to be analyzed in order to provide timely predictions. By replicating processes that crunch that data, Google is able to balance the load between more processes returning faster results.
Caching is a special form of replication. It’s a copy of a resource, generally close to the user accessing that resource. You’re probably familiar with your browser’s cache. To load pages faster, your browser saves recently visited website data locally for a limited time.
Caching and replication bring a serious drawback that can adversely affect scalability: consistency. While total consistency is impossible to reach, to what extent inconsistencies can be tolerated depends on the application.
Cluster, Grid, and Cloud Computing
Distributed computing systems can be categorized into three categories:
Cluster computing — is a collection of similar machines connected through a high-speed local-area network. Each node runs on the same hardware and OS. Cluster computing is often used for parallel programming in which a single compute intensive program runs in parallel on multiple machines.
Each cluster consists of a collection of compute nodes monitored and managed by one or more master nodes. The master handles things such as allocation of worker nodes to a particular process and management of request queues. It also provides the system interface for users. In short, the master manages the cluster while the workers run the actual program.
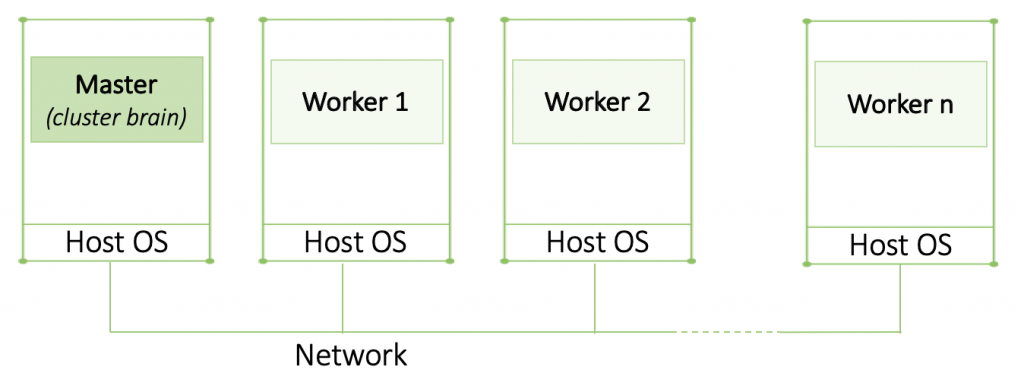
Grid computing — composed of nodes with stark differences in hardware and network technology. Today’s trend towards specifically configuring nodes for certain tasks has led to more diversity which is more prevalent in grid computing. No assumptions are made in terms of similarity in hardware, OS, network, or security policies. Note that in daily tech jargon cluster is generally used for both cluster and grid computing.
Cloud computing — is a pool of virtualized resources hosted in a cloud provider’s datacenter. Customers can construct a virtualized infrastructure and leverage a variety of cloud services. Virtualized means that resources appear to be a single piece of hardware (e.g. individual machine or storage facility) but are actually a piece of software running on that hardware. A virtual machine (VM), for instance, is code that ‘wraps around’ an application, pretending to be hardware. The code running inside the VM thinks the VM is a separate computer, hence the term “virtual” machine. To the client, it seems as if they are renting their own private machine. In reality, however, they are likely sharing it with other clients. The same applies to virtual storage or memory. These virtualized resources can be dynamically configured enabling scalability: if more compute resources are needed, the system can simply acquire more.
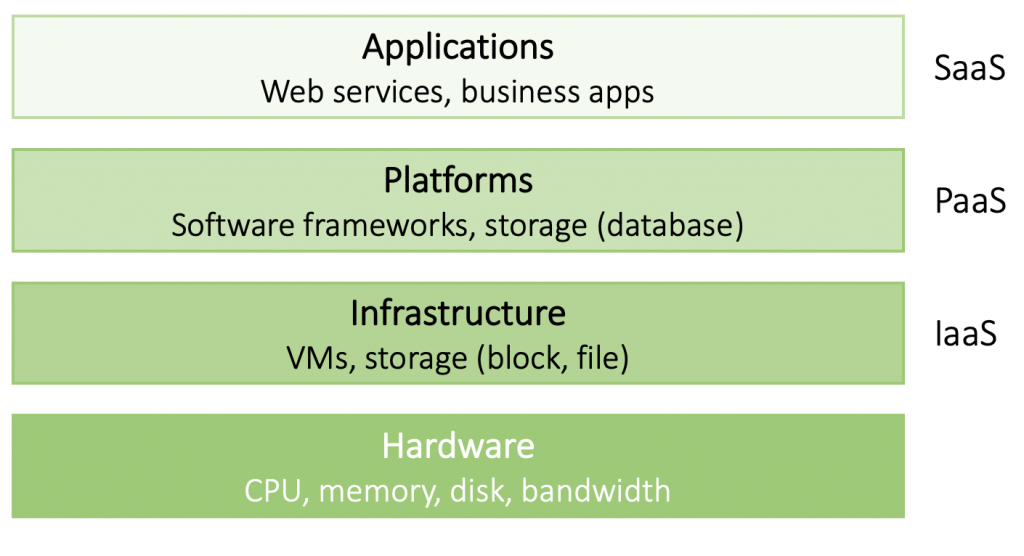
Since cloud computing is so prevalent, let’s have a quick look at how it’s organized. We can differentiate four layers:
- Hardware — consisting of processors, routers, power, and cooling systems. They ‘live’ in the cloud providers’ data center and are never seen by the user.
- Infrastructure — represents the backbone of cloud computing. Customers rent infrastructure consisting of VMs, virtual storage and other virtualized compute resources, and less frequently even bare metal machines.
- Platform — provides developers with an easy way to develop and deploy applications in the cloud. Through a vendor-specific application programming interface (API), developers can upload and execute programs.
- Application — Cloud-hosted applications that developers can further customize or end-user applications.
Each layer represents an additional abstraction layer, meaning the user does not have nor need any knowledge about the underlying layers. Cloud providers offer a variety of services on each layers:
- Infrastructure-as-a-Service: Amazon S3 or EC2;
- Platform-as-a-Service: Google App engine or MS Azure;
- Software-as-a-Service: Gmail, YouTube, Google Docs, Salesforce etc.
Cloud Native, Delivering the Next Level of Openness and Portability
With the rise of cloud native and open source technologies, we are hearing a lot about openness, portability, and flexibility. Yet the desire to build distributed systems based on these principles is by no means new. Cloud native technologies are bringing these concepts to a whole new level, however.
Before we get into the ‘how’, let’s step back and talk about what cloud-native technologies are. Similar to cloud managed services, cloud native technologies, among other things, provide services like storage, messaging, or service discovery. Unlike cloud managed services, they are infrastructure independent, configurable, and in some cases more secure. While cloud providers were the driving force behind these services (which brought us unprecedented developer productivity!), open source projects and startups started to codify them and provide analogous services with one big advantage: they don’t lock you in. Now, the term cloud native can be a little misleading. While developed for the cloud, they are not cloud bound. In fact, we are increasingly seeing enterprises deploying these technologies on-premise.
So, what’s the big deal? The new stack, as cloud native technologies are often referred to, is enabling organizations to build distributed systems that are more open, portable, and flexible than ever before, if implemented properly. Here are some examples of cloud native innovation:
Containers — could be interpreted as the new lightweight VMs (though they may be deployed on VMs). Containers are much more infrastructure independent and thus more portable across environments. Additionally, being more lightweight, they spin up faster and occupy less resources than VMs.
Kubernetes — functions as some sort of data center OS managing resources for containerized applications across environments. If implemented correctly, Kubernetes can serve as an infrastructure abstraction where all your infrastructures (on-prem and clouds) become part of a pool of resources. That means that developers don’t have to care where their applications run, they just deploy them on Kubernetes and Kubernetes takes care of the rest.
Cloud native services — Cloud native services are the new cloud independent counterparts of cloud managed services. Services include storage (e.g. Portworx, Ceph, or Rook), messaging (e.g. RabbitMQ), or service discovery and configuration (e.g. etcd). They are self-hosted offering a lot more control and work across environments.
Microservices — are applications that are broken down into micro components, referred to as services. Each service is self-contained and independent, and can thus be added, removed, or updated while the system is running. This eases extensibility even further.
Interoperability and extensibility — Cloud native technologies led to a shift from large and heavy technology solutions that lock customers in towards modular, open technologies you can plug and play into your architecture if the architecture was built in a layered fashion according to architectural best practices.
Cloud native technologies have the potential to create a truly open and flexible distributed system that future proofs your technology investments. This potential benefit is often compromised by building systems with a specific use case in mind and tying it to a particular technology stack or infrastructure. This ultimately transforms open source components into opinionated software negating the very benefits we all applaud.
To avoid this, systems should be built based on architectural best practices such as a clean separation between layers. While it requires a little more planning and discipline early on, it will speed adoption of newer technology down the line allowing organizations to pivot quickly with market demand.
Because this is so crucial, an enterprise-grade Kubernetes platform, which will be at the core of your cloud native stack, should be built on these very principles. So do your research, understand the implications, and keep future requirements in mind. Cloud native technologies offer the opportunity for a fresh new start — don’t lock yourself in again.