
If you’re migrating your applications to containers, you’ll need a container orchestration platform and, if you’re reading this article, chances are you’re considering Kubernetes.
You may ask yourself: What’s under the hood of this incredibly popular container orchestration engine? How does it deliver the potential of a future-ready, solid and scalable solution for production-grade, containerized applications? (Note the deliberate use of the word “potential,” we’ll come back to why we inserted that word later).
In this article, we’ll discuss how Kubernetes works and why it has the potential (there’s that word again) to support enterprise-scale software/container management.
What’s Kubernetes?
If your researching Kubernetes architecture, you probably already know what it is, so let’s just summarize it to ensure we are on the same page. Kubernetes (often abbreviated as k8s) is a container orchestration framework for containerized applications. It can be viewed as some type of datacenter OS which manages the resources across your environments.
Not only does Kubernetes have all the needed capabilities to support your complex containerized apps, but it’s also the most convenient framework on the market for both developers and operations.
Kubernetes groups containers that make up an application into logical units for easy management and discovery. It’s particularly useful for microservice applications — apps broken down in ‘micro’ components functioning as independent services.
Although Kubernetes runs on Linux, it is platform-agnostic and can be run on bare metal, virtual machines, cloud instances, or OpenStack.
What’s Under the Hood?
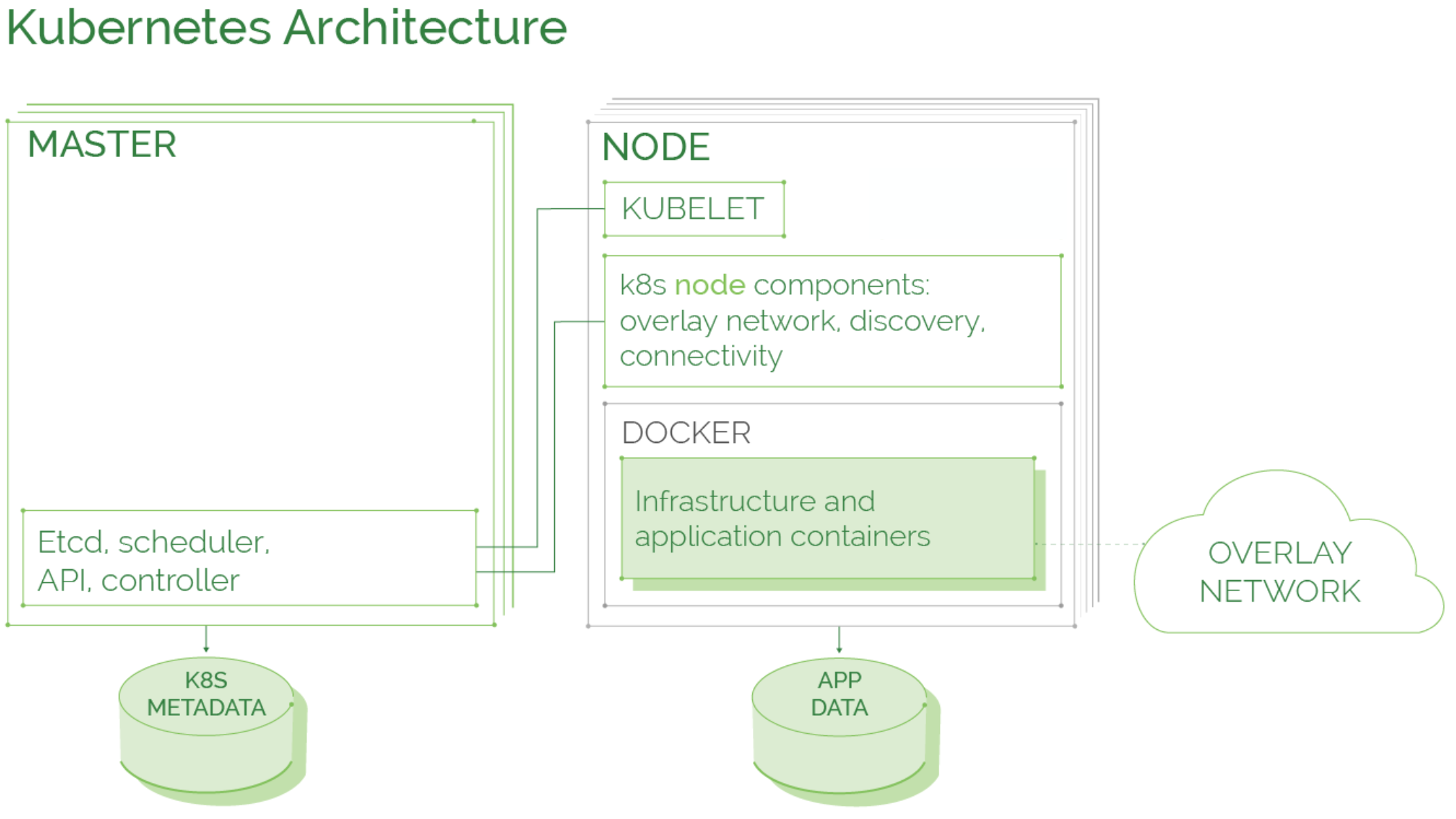
To understand how Kubernetes works, let’s look at the anatomy of Kubernetes. Each cluster is composed of a master and multiple worker nodes.
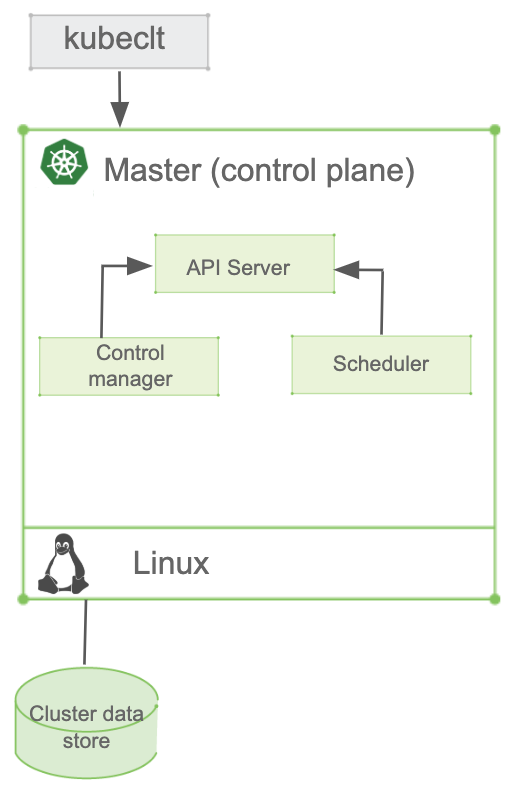
The Kubernetes Master Node
The master node is the cluster control panel or control plane. This is where decisions are made about the cluster, such as scheduling, and detecting/responding to cluster events. Master components can run on any node in the cluster. Key components are:
API Server — The only Kubernetes control panel component with a user-accessible API and the sole master component that you’ll interact with. The API server exposes a restful Kubernetes API and consumes JSON manifest files.
Cluster Data Store — Kubernetes uses “etcd.” This is a strong, consistent, and highly-available key value store that Kubernetes uses for persistent storage of all API objects. Think of it as the “source of truth” for the cluster.
Controller Manager — Known as the “kube-controller manager,” it runs all the controllers that handle routine tasks in the cluster. These include the Node Controller, Replication Controller, Endpoints Controller, and Service Account and Token Controllers — each of which works separately to maintain the desired state.
Cloud Controller Manager (beta in Kubernetes 1.15) – this is a relatively new component intended to separate cloud/infrastructure provider specific controller functionality from generic Kubernetes controllers. As of Kubernetes 1.15, the cloud provider related functionality can still be performed by the Controller Manager. However, it will soon move completely to Cloud Controller Manager.
Scheduler — The scheduler watches for newly-created pods (groups of one or more containers) and assigns them to nodes.
Dashboard (optional) — The Kubernetes’ web UI that simplifies the Kubernetes cluster user’s interactions with the API server.
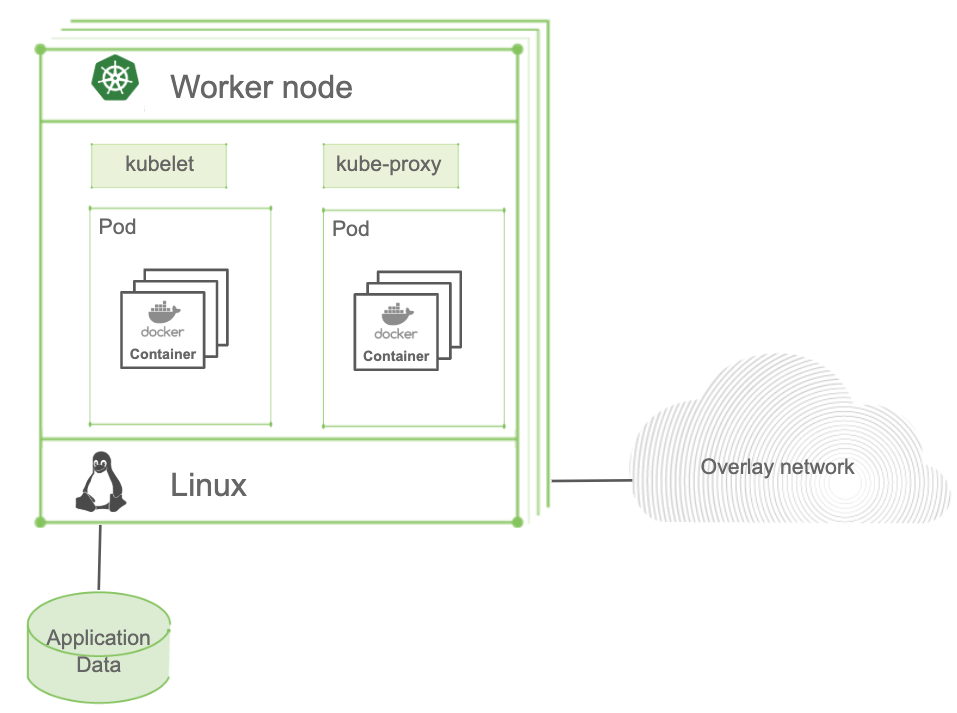
Kubernetes Worker Nodes
While the master manages and monitors the cluster, worker nodes run the actual containerized applications providing the Kubernetes runtime environment.
Worker nodes comprise a kubelet: the primary node agent. It watches the API server for pods that have been assigned to its node. The kubelet carries out tasks and maintains a reporting backchannel of pod status to the master node.
Inside each pod there are containers, kubelet runs these generally via Docker (pulling images, starting and stopping containers, etc.). It also periodically executes any requested container liveness probes. Kubernetes supports multiple runtimes, including Docker, CRI-O, and Containerd.
Another component is the kube-proxy, the network brain of the node which maintains network rules on the host and performs connection forwarding. It’s also responsible for load balancing across all pods in the service.
Kubernetes Pods
A pod is a group of one or more containers (e.g. Docker) with shared storage/network. Each pod contains specific information on how containers should be run. Think of them as a ring-fenced environment to run containers.
Pods are also the scaling unit. App components are scaled up or down by adding or removing pods.
Tightly coupled containers can run in a single pod (where each shares the same IP address and mounted volumes). Otherwise, each container runs in its own pod.
Pods are deployed on a single node and have a definite lifecycle. They can be pending, running, succeeding, or failing. But once gone, they are never brought back to life. Now dead, a replication controller or other controller must create a new one.
How Does It All Work Together?
Now that we’ve looked at the individual components, let’s take a look at how Kubernetes automates the deployment, scaling, and operation of containerized applications.
Like all useful automation tools, Kubernetes uses object specifications or blueprints to run your system. Simply tell Kubernetes what you want, and it does the rest. A useful analogy is hiring a contractor (albeit a good one) to renovate your kitchen. You don’t need to know stage-by-stage what they’re doing. You just specify the outcome, approve the blueprint and let them handle the rest. Kubernetes works in the same way. Kubernetes operates on a declarative model, object specifications provided in so-called manifest files declare cluster characteristics. There’s no need to specify a list of commands, as Kubernetes will ensure the cluster always matches the desired state.
Building your Cluster Blueprint
Kubernetes blueprints consist of several building or Lego® blocks. You simply define the blocks you’ll need and Kubernetes brings it to life. These blocks include things like the specifications to set-up containers. You can also modify the specifications of running apps and Kubernetes will adjust your system to comply.
Automating these otherwise cumbersome manual processes was quite a revolution which is why Kubernetes has caught on so quickly! Just like the cloud revolutionized infrastructure management, Kubernetes and other systems are taking the application development space by storm. Now DevOps teams have the potential (there’s that word again) to deploy, manage, and operate applications with ease. Just send your blueprints to Kubernetes via the API interface in the master controller.
There are several available Lego-like blocks that can help define your blueprint. Some of the more important ones are:
Pods — A sandbox-like environment that doesn’t play a major role except for hosting and grouping containers.
Services — An object that describes a set of pods that provide a useful service. Services are typically used to define clusters of uniform pods.
Persistent Volumes — A Kubernetes abstraction for persistent storage. Kubernetes supports many types of volumes, such as NFS, Ceph, GlusterFS, local directory, etc.
Namespaces — This is a tool used to group, separate, and isolate groups of objects. Namespaces are used for access control, network access control, resource management, and quoting.
Ingress rules — These specify how incoming network traffic should be routed to services and pods.
Network policies — This defines the network access rules between pods inside the cluster.
ConfigMaps and Secrets — Used to separate configuration information from application definition.
Controllers — These implement different policies for automatic pod management. There are three main types:
- Deployment — Responsible for maintaining a set of running pods of the same type.
- DaemonSet — Runs a specific type of pod on each node based on a condition.
- StatefulSet — Used when several pods of the same type are needed to run in parallel, but each of the pods is required to have a specific identity.
The Kubernetes Agent
Agents on each node enable Kubernetes to run and control a set of nodes on virtual or physical machines simultaneously. These agents communicate with the master via the same API the user used to send the Kubernetes blueprint to the master. Aware of all node characteristics (e.g. available RAM, CPU, etc.), the agents report them to the master which, based on this information, can decide which containers to run on the nodes.
The master node runs several Kubernetes components. Together, these make all control decisions such as which container should be started on which node with what configuration.
In addition, the master and agent may interact with a cloud provider and manage additional cloud resources such as load balancers, persistent volumes, persistent block storage, network configuration, and a number of instances. The master can be a single instance running Kubernetes components or a set of instances to ensure high availability (so-called multi-master clusters). A master can also serve (in certain configurations) as a node to run containers, although this is not recommended for production.
Kubernetes Reality vs its Potential
Recall our statement about Kubernetes’ “potential?” While Kubernetes has all the needed components for a solid architectural foundation and scalability for your containerized applications, it’s not a ready-to-use platform. For that, you’ll need an entire stack — Kubernetes and Docker, though at the core, are only one part of the solution. The Kublr Platform is built around open source Kubernetes adding all the components required to run at scale in production.
The Kublr Platform
Operational and Governance Features around Open Source Kubernetes
The Kublr Platform adds operational and governance features around open source Kubernetes. It enables organizations to deploy, run, and manage Kubernetes clusters in multiple environments, whether in the cloud, on-premise, hybrid, or even in air-gapped environments by:
- Automating the deployment and proper configuration of open source Kubernetes components.
- Adding enterprise-grade operational, security, and governance components.
- Providing the ability to separate out management and control to organizational functions and business units.
- Enabling multi-cloud, hybrid, and on-premise deployment and management from a single control plane.
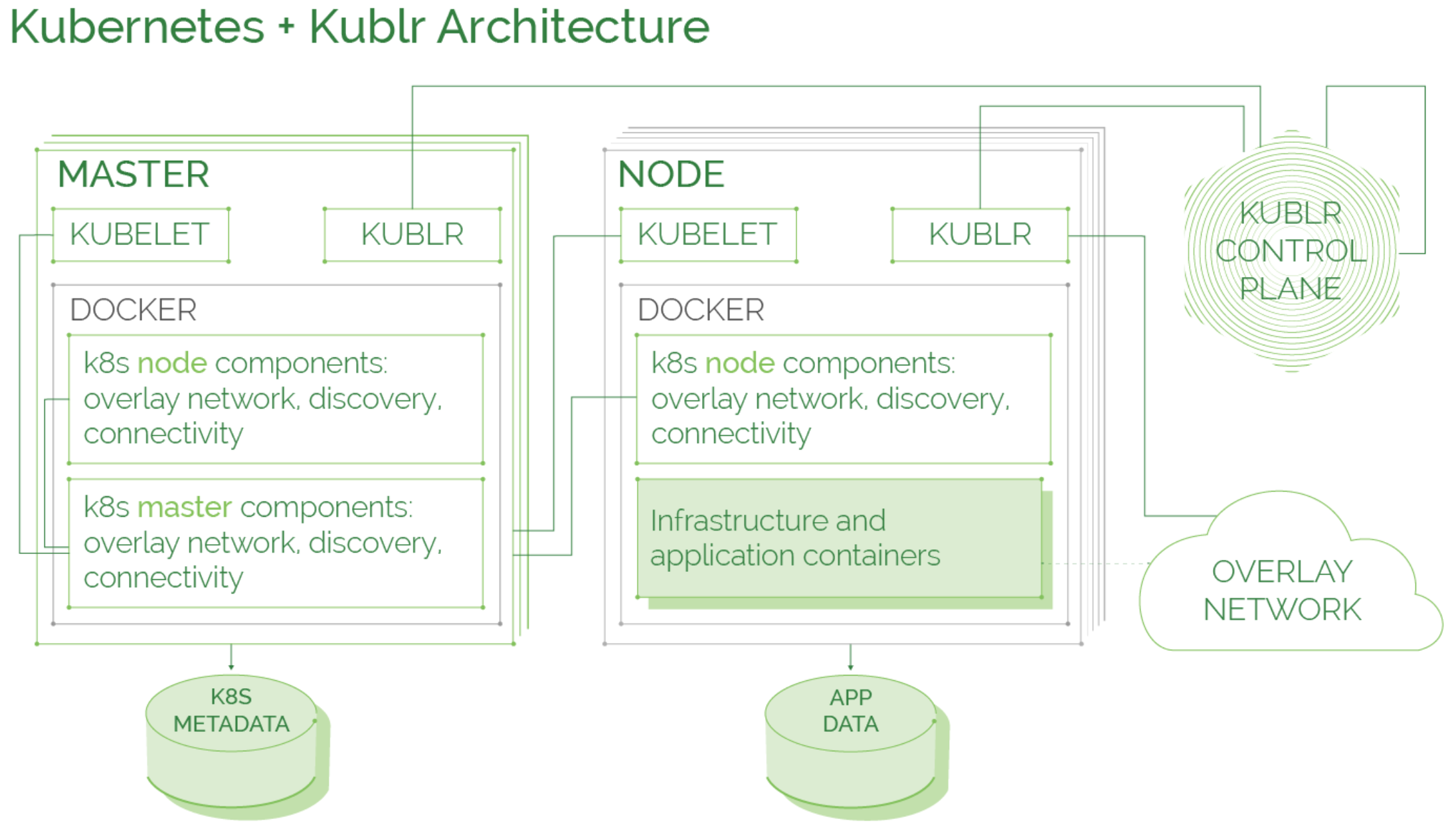
Kublr uses unmodified standard Kubernetes components, direct from Google repositories, and Kubernetes configuration best practices to ensure secure, reliable, and conformant Kubernetes setup.
Kublr deploys each of the standard Kubernetes components, except for the kubelet, inside Docker containers. This ensures the solution is more portable and simplifies support for multiple operating systems and environments.
The majority of the work on the infrastructure and Kubernetes layers is done by the Kublr Agent. The agent is a single lightweight binary that is installed by Kublr on each node in the cluster. The Kublr Agent performs the initial setup and configuration of a node, including the configuration of the operating system and Kubernetes components. It also proactively monitors the health status of the node and the components installed on it, and restores them to a healthy state should any failure occur.
Each of the Kublr Control Plane components, including centralized logging based on Elasticsearch stack, monitoring based on Prometheus/Grafana, identity broker, user interface, and other components are automatically deployed using Helm packages.
Operational and Governance Features
Kublr provides an intuitive UI that operations teams can use to deploy and manage clusters. It enables users to see the status and health of clusters at a glance, and provides domain specific deployment screens.
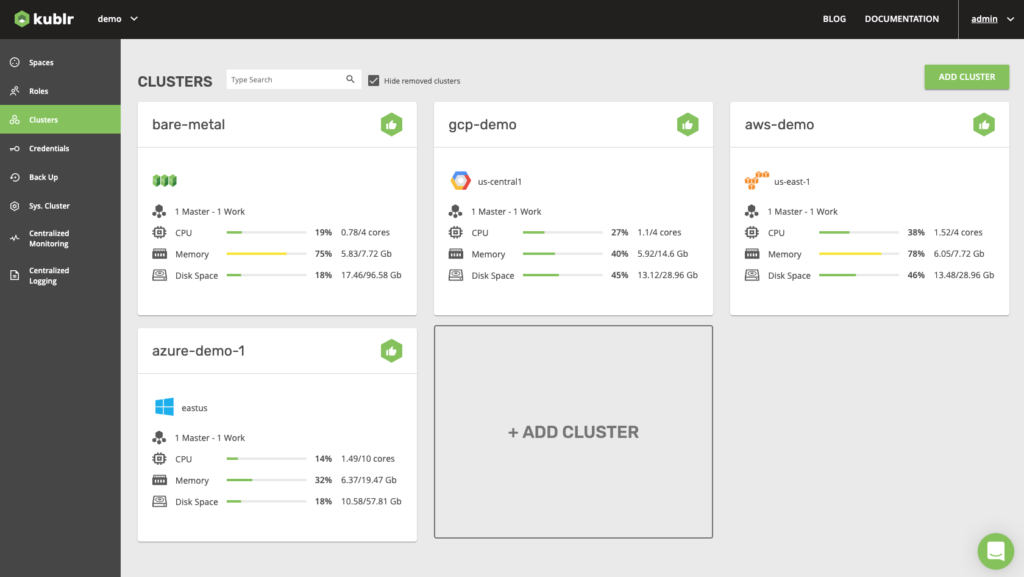
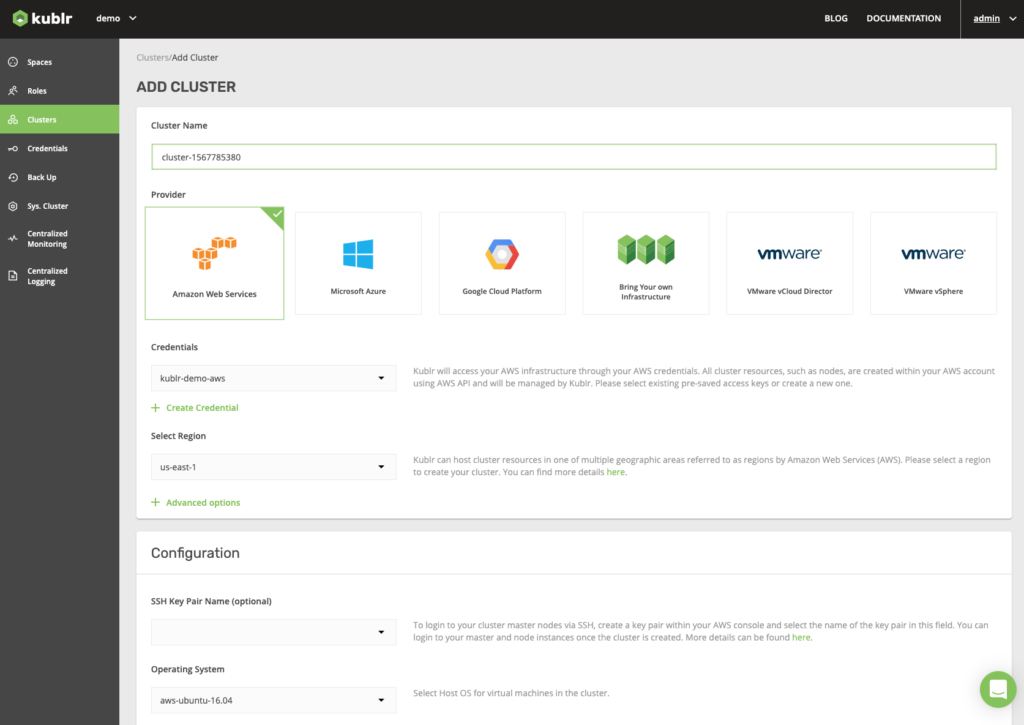
Kublr’s unique centralized logging and monitoring provides a single pane of glass for cluster information across multiple environments. For more details on how Kublr works, visit this page.
While there are multiple platforms to choose from, they all differ somehow in approach and focus — so we recommend doing your research before selecting a platform as the differences, though subtle at first glance, will have a big impact.
Most organizations will need to manage multiple clusters for multiple groups in diverse environments. They will also need to consider how Kubernetes will be integrated with existing technologies and procedures, from databases and storage to DevOps processes and tooling. If these are the capabilities you’re looking for, schedule a live demo. A technical advisor from the Kublr would be more than happy to give you a quick tour of the platform.