
As technology becomes a key differentiator, business leaders are increasingly engaging in strategic discussions with IT leaders to better understand how the solutions they develop will meet their business needs. At this juncture, it’s critical that they have a basic understanding of how software and system architecture work and how decisions made choosing the right architecture will affect the final business application or solution in terms of usability, scalability, flexibility, and more. This high-level overview will hopefully provide the needed context to better navigate such exchanges. This treatment would be of particular interest to system architects that need to understand and deploy and manage distributed cloud native systems.
As outlined in our previous article, distributed systems are complex pieces of software. To master this complexity, systems must be properly organized. Let’s start by distinguishing between two key organization concepts: software architecture and system architecture.
Software architecture refers to the logical organization of a distributed system into software components. Instead of one big monolithic application, distributed systems are broken down into multiple components. The way in which these components are broken down impacts everything from system performance to reliability to response latency.
System architecture refers to the placement of these software components on physical machines. Two closely related components can be co-located or placed on different machines. The location of components will also impact performance and reliability.
The resulting architectural style ultimately determines how components are connected, data is exchanged, and how they all work together as a coherent system.
Software Architecture
There are many different architectural styles, including layered architectures, object-based, service-oriented architectures, RESTful architectures, pub/sub architectures, and so on. The style used ultimately depends on the application. Additionally, as you start building more complex, interconnected systems, distributed systems grow in size. As a result, processes such as communication must be simplified and streamlined.
1. Layered Architecture
Let’s start with layered architectures. In a layered architecture, components are organized in layers. Components on a higher layer make downcalls (send requests to a lower layer). While lower layer components can make upcalls (send requests up), they usually only respond to higher layer requests.
Consider Google Drive/Docs as an example:
- Interface layer: you request to see the latest doc from your drive.
- Processing layer: processes your request and asks for the information from the data layer.
- Data layer: stores persistent data (aka your file) and provides access to higher-level layers.
The data layer returns the information to the processing layer which in turn sends it to the interface where you can view and edit it. While it feels like one cohesive process, it’s broken down into three (or more) components on three distinct layers. Each layer may or may not be placed on a different machine (this is a system architecture consideration).
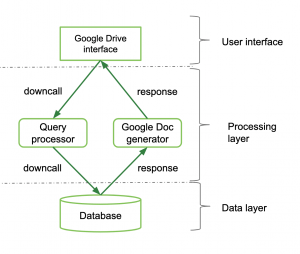
Simplified organization of a Google Drive/Doc view request
2. Object-Oriented, Service-Oriented Architectures, Microservices, and Mesh Architectures
Object-oriented, service-oriented architectures (SOA), microservices, and “mesh” architectures are all more loosely organized and represent an evolutionary sequence. While we’ve grouped them together, object-oriented isn’t an architectural style but rather a programming methodology that makes service-oriented architectures (SOAs) and microservices possible.
OBJECT-BASED ARCHITECTURAL STYLES
Object-oriented programming is a methodology generally used in the context of monolithic apps (although it’s also used in more modern architectures). Within the monolith, logical components are grouped together as objects. While they are distinguishable components, objects are still highly interconnected and not easy to separate. Object-oriented is a way to organize functionality and manage complexity within monoliths.
Each object has its own encapsulated data set, referred to as the object’s state. You may have heard of stateful and stateless applications that refer to whether or not they store data. In this context, state stands for data. An object’s method is the operations performed on that data.
Objects are connected through procedure call mechanisms. During a procedure call, an object “calls” on another object for specific requests. So when you hear ”procedure call”, think of a request.
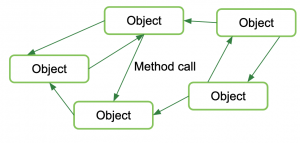
Object-based architectural style
Service-Oriented Architecture
Objects form the foundation of encapsulating services into independent units leading to the development of SOAs. Services are self-contained, independent objects that make use of other services. Communication happens over a network via “messages” sent to each interface.
Microservices
Microservices are the next step in this evolutionary sequence. These microservices are smaller than services in an SOA, less tightly coupled, and more lightweight. The more significant difference from a business perspective, however, is their ability to decrease time to market.
Unlike with SOAs, where developers need to design and map out all interactions and interfaces before deploying a service (a process that can take months), microservices are more independent, allowing developers to push out updates without worrying about architectural details. Additionally, developers can use any programming language they want. Selecting the best language for a particular program further increases speed and thus time to market.
Mesh architectures
Mesh architectures are formed by services or processes running on nodes that cannot be easily accounted for. They may connect and disconnect frequently, some may not even use the internet. These services establish temporary peer-to-peer connections and can stay anonymous throughout the process. Examples are peer-to-peer technologies like TOR, torrents, p2p messengers, blockchain, etc.
Mesh architectures bring two additional qualities:
- Interacting services/processes are more uniform: there may be just a few or even one type of service participating in a mesh network. They are considered equal to each other — equally trustworthy or untrustworthy if we are speaking about security, for instance. This is quite different from traditional service-based architectures where there are usually dozens of non-uniform services.
- There is a higher emphasis on its distributed nature.
Mesh technologies are able to remain efficient even in highly unstable environments where connectivity between components is easily broken. Some components, in some cases even most components, are not directly connected. Instead, they communicate over multiple ”hops” via other system elements (messages “hop” or ”jump” from one element to another until reaching its destination).
Although you can see the fact that there is an evolution from object-oriented programming to SOAs, microservices, and mesh architectures, it doesn’t mean that this methodology is obsolete. Object-oriented merely refers to the separation of blocks inside a component or monolith. It’s a methodology that was, and still is, used. In fact, you can develop object-oriented microservices where microservices are composed of objects.
3. Representational State Transfer (REST) or RESTful Architectures
REST is an architectural style widely adopted for the Web (a Web-native architecture). A distributed system is viewed as a huge collection of resources, individually managed by components. Resources, in the context of REST, are a unique form of services that follow these conventions:
- They understand a limited set of commands, often restricted to put, get, delete, and post
- There is only one (URL-based) naming scheme
- Resource interfaces follow the same conventions and semantics
- Messages are fully self-described
- After executing an operation on a resource, the resource forgets everything about the call from the client, except for the resulting changes in the service state
That last property is called stateless execution.
Why all these restrictions on commands and interface specs? Well, just think of the vastly diverse systems that must communicate over the internet. By standardizing interfaces and reducing commands, developing compatible systems is much easier. REST is basically a simplification to deal with the diversity in a huge distributed system like the internet.
Despite these restrictive commands, developers have enough flexibility to express anything they need. That’s because the URL, a descriptive resource address, contains all the needed details to express operations. Let’s take HTTP GET http://amazon.com/shoppingcart/546/items/12345 as an example. This command is a request to get items “12345” from shopping cart “546.” All the details about what it is and where to find it are expressed in the URL.
4. Publish-Subscribe Architectures
Publish-subscribe or, as a techie would say, pub/sub, is an even more loosely coupled architecture that allows processes to easily join or leave. The key difference here is how services communicate. Instead of calling and getting a response, services send one-way, usually asynchronous messages, generally not to a specific receiver. They rely on a configurator, administrator, or developer to configure who’ll receive what message. In some cases, the receivers themselves can sign up to receive messages. This, by the way, is how you get your breaking news push notifications. The Washington Post, for instance, publishes a news item categorized as “breaking news” and whoever subscribes to these updates will receive it.
Pub/sub is most relevant for mobile applications where network reliability is often an issue. If a mobile app relies on service calls, you’ll get a bad user experience as soon as you lose connectivity. With pub/sub, on the other hand, you’ll simply get the update later (e.g. worst-case scenario, everyone else finds out about Trump’s latest tweet before you do), but the user experience itself isn’t affected.
System Architectures
System architecture encompasses decisions as to where to place specific software components. Should certain components be placed on the same server or on different machines? Enterprises may have a specific high-speed processing server or high-end reliable storage facility that they’ll want to leverage for specific components. These decisions will lead to different types of architectural organizations. We can broadly categorize them into centralized and decentralized organizations.
1. Centralized Organizations: Client-Server Systems
A server is a process implementing a specific service (e.g. database service). The client is a process requesting that service from a server. The client sends the request and waits for the reply (request-reply behavior). Where these processes are physically distributed will lead to different multitiered architectural styles.
Remember the three layers discussed above (interface, processing, data layer)? While we distinguish between three logical levels, there are several ways to physically distribute a client-server application across machines.
The simplest organization is using two types of machines: 1) a client machine with the user interface (layer one), and 2) the server interface containing the program implementing the process and the data (layers two and three). In this case, everything is handled by the server while the client is nothing more than a dumb terminal. This is called a (physically) two-tiered architecture. However, there are other ways to separate these three layers on two machines. Possibilities range between separation, as mentioned above, to having everything, except the stored data, running on the client machine. You can see these different variations in the graphic below.

Variations of physically two-tiered three-layered architectures.
In (physically) three-tiered architectures, one of the servers also has to act as a client. The application is spread across three machines, one client and two servers. One of the servers may need input from the other server to process the client request, acting as a client.
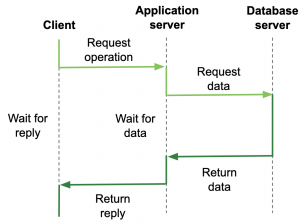
Three-tier architecture: one client and two servers with the app server also acting as a client.
Multitiered client-server architectures are a direct consequence of dividing distributed applications into a user interface, processing components, and data-management components. Different tiers correspond directly with the logical organization of applications (software architecture corresponds to system architecture). This is called vertical distribution in which logically different components are placed on different machines. This allows for each machine to be tailored to a specific function, for example, placing the processing layer on a high-end processing server.
2. Decentralized Organization: Peer-to-Peer Systems
In modern architectures, clients and servers themselves are distributed, in so-called horizontal distribution. A client or server may be physically split, but each part operates on its own share of complete data thus balancing the load. So, instead of having one data store all components have access to, potentially turning into a bottleneck, each component has its own dataset. These are called peer-to-peer systems. Each process acts as client and server at the same time, often referred to as servant.
Peer-to-peer architectures evolve around the question of how to organize processes in an overlay network — a network in which nodes are formed by processes and links represent possible communication channels.
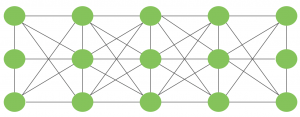
Peer-to-peer system network connected via an overlay network.
As we’ve seen, there are multiple ways of organizing applications into logical components (software architecture considerations). Whether layered, object/service-oriented, REST, or pub/subscribe is the best approach largely depends on the application. These components are then placed on different physical machines (system architecture considerations), either in a client-server or peer-to-peer fashion. In our article “Primer: Understanding the Cloud Native Impact on Architecture,” we discuss how cloud native is breaking the barriers of more traditional technologies, enabling enterprises to quickly adapt to market demands.
As usual, a big thanks to Oleg Chunikhin who was instrumental in getting all technical details right. And to Evgeny **Pishnyuk who also provided valuable feedback.